The implications of Hyper-threading on machines with
Simulator Workloads
by Vince Weaver ( vince _at_ csl.cornell.edu )
11 November 2005
The Problem
I disabled hyper-threading on the sampaka and
cluizel clusters, a decision multiple people have questioned.
I have conducted a set of experiments to determine the performance
implications of hyper-threading for the most common workload of the clusters,
namely long running processor simulations.
The Experiment
The test was run on "cluizel39", one node of the cluizel cluster.
The node was running Linux 2.6.11 with perfctr and bmcsensor support
patched in. This kernel does have a hyper-threading aware
scheduler.
The node has the following hardware:
- Dual Intel Pentium IV Xeon Processors, 2.8GHz
- 2GB of RAM. 8kB L1 D-cache. 12kB trace cache. 512kB unified L2 cache.
- No disk. All I/O via NFS over 100MB/s ethernet.
The test program was the alpha version of simple-scalar 4.0.
The test benchmark was equake from the spec2k benchmarks, compiled
statically on boulder. The Minnispec lgred.in input was used.
Multiple identical copies of the simulation were launched simultaneously
via a script, and the resulting time it took each thread to complete
was recorded.
The test was conducted both with and without Hyperthreading enabled
via the BIOS.
Results
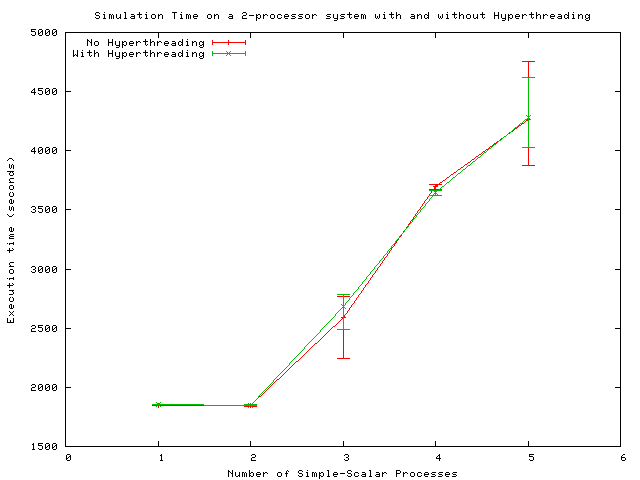
The errorbars indicate maximum and minimum time of the simultaneous
runs, while the plotted line connects the average times.
Note the errorbars are much wider for odd-numbers of processes.
This is due to the way the Linux scheduler works.
In the 3-thread case, one process gets a CPU to itself, thus finishing
much sooner than the two processes that must share the remaining CPU.
Bouncing processes from cpu to cpu is avoided because
it can cause poor cache performance.
There is no significant performance gain from hypertheading; in fact
in the 3 thread case the hyperthreading performance is worse.
These results are far from the 25-30% maximum performance gains
Intel claim are possible.
Also note that the OS does take hyperthreading into account when
scheduling. If it didn't, then the 2 and 4 cpu cases would be worse for
the HT case (as the scheduler would have assigned the jobs to the first
two cpus it saw (parent and sibling of cpu#0), making one cpu overload
and leaving the other idle).
Conclusion
Hyper-threading would not be a benefit on our clusters.
In the two process case, the machine performs identically
whether hyperthreading is enabled on disabled.
When running more than 2 threads, hyperthreading has no significant
impact on the time taken to finish a job. In fact, hyperthreading
can make performance slightly worse.
There are numerous other reasons to disable hyperthreading:
- RAM Pressure: With twice as many threads, each ends up
with half as much available RAM.
- Confuses the batch scheduler: NBS does not have special
support for hyperthreads; it sees each as a full processor.
Thus it will put 4 jobs on one node and leave others idle.
- Licensing confusion: Many commercial software products
will charge twice as much for a license for a hyper-threaded CPU
- User confusion: Userspace utilities like "top" report
hyperthreaded CPU's as being 2 distinct CPUs. Thus users
will run twice as many processes to get "full" utilization even
if it doesn't make sense performance-wise.
- Security Reasons:It is reported that information can be
leaked between hyperthreads