 |
 |
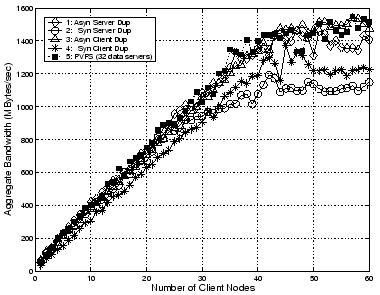 |
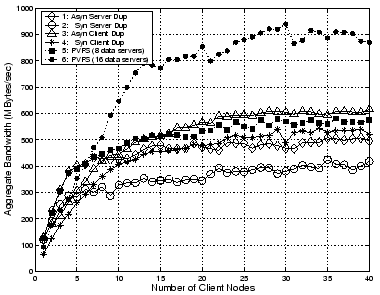
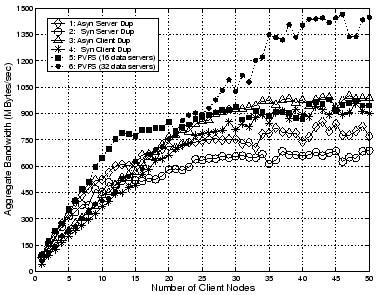
In Protocol 2, the write process from the clients to the primary group and the duplication process from the primary group to the backup group are pipelined and thus the performance is only slightly inferior to that of Protocol 1 when the primary server is lightly loaded (e.g., with fewer than 5 clients). As the workload on the primary server increases, the performance of Protocol 2 lags further behind that of Protocol 1.
When the number of client nodes is smaller than the number of server nodes, Protocols 1 and 2 outperform Protocols 3 and 4, since more nodes are involved in the duplication process in the first two protocols than in the last two. On the other hand, when the number of client nodes approaches and surpasses the number of server nodes in one group, the situation reverses itself so that Protocols 3 and 4 become superior to Protocols 1 and 2. To achieve a high write bandwidth, we have designed a hybrid protocol, in which Protocol 1 or 2 is preferred when the client node number is smaller than the number of server nodes in one group, and otherwise Protocol 3 or 4 is used. When the reliability is considered, this hybrid protocol can be further modified to optimize the balance between reliability and write bandwidth. This will be explained in detail later in this paper.
| Number of Data Servers in One Group | ||||||
| Protocol | 8 | 16 | 32 | |||
| |
|
|
|
|
|
|
| 1(Server Asynchronous Duplication) | 492 | 87 | 796 | 86 | 1386 | 94 |
| 2(Server Synchronous Duplication) | 391 | 68 | 660 | 71 | 1114 | 75 |
| 3(Client Asynchronous Duplication) | 604 | 106 | 974 | 104 | 1501 | 101 |
| 4(Client Synchronous Duplication) | 528 | 93 | 905 | 97 | 1218 | 82 |
| 5(PVFS with half # of nodes) | 567 | 100 | 929 | 100 | 1482 | 100 |
| 6(PVFS with same # of nodes) | 929 | 164 | 1482 | 160 | ||
Table II summarizes the average peak aggregate
write performance of the four protocols in the saturation region,
along with their performance relative ratio to the PVFS with half
the number of data servers and the same number of data servers,
respectively. The aggregate write performance of Protocol 1 is
nearly ![]() ,
, ![]() and
and ![]() better than that of Protocol 2
under the three server configurations, respectively, with an
average improvement of
better than that of Protocol 2
under the three server configurations, respectively, with an
average improvement of ![]() . The performance of Protocol 3 is
nearly
. The performance of Protocol 3 is
nearly ![]() ,
, ![]() and
and ![]() better than that of Protocol 4,
under the three configurations respectively, with an average
improvement of
better than that of Protocol 4,
under the three configurations respectively, with an average
improvement of ![]() . While the workload on the primary and
backup groups are well balanced in Protocols 3 and 4 due to the
duplication symmetry initiated by the client nodes, in Protocol 1
and 2 the primary group bears twice the amount of workload as the
backup group because of the asymmetry in the duplication process.
As a result, the peak performance of Protocol 3 is better than
that of Protocol 1, while Protocol 4 outperforms Protocol 2
consistently.
. While the workload on the primary and
backup groups are well balanced in Protocols 3 and 4 due to the
duplication symmetry initiated by the client nodes, in Protocol 1
and 2 the primary group bears twice the amount of workload as the
backup group because of the asymmetry in the duplication process.
As a result, the peak performance of Protocol 3 is better than
that of Protocol 1, while Protocol 4 outperforms Protocol 2
consistently.
Compared with the PVFS with the same number of data servers, the
server driven protocols 1 and 2 improve the reliability at the
expense of 46-58% write bandwidth and the client driven protocols
3 and 4 cost around ![]() and
and ![]() write bandwidth
respectively. Compared with the PVFS with half the number of data
servers, as shown in Table II, such cost is not
only acceptable in most cases, but it is also at times negligible
or even negative, especially for Protocol 3. In Protocol 3, when
the total number of clients is large enough, the extra work of
duplication at the client side will not influence the aggregate
write performance since the data servers have already been heavily
loaded and their I/O bandwidth have been saturated. Furthermore,
the application running on a client node will consider its write
operations completed as long as the client has received at least
one acknowledgment among each mirroring pair, although some
duplication work may still proceed, transparent to the
application.
Since the data servers are not dedicated and their CPU, disks,
memory and network load are different, Protocol 3 chooses the
response time of the less heavily loaded server in each mirroring
pair and thus surpass the PVFS with half the number of data
servers.
write bandwidth
respectively. Compared with the PVFS with half the number of data
servers, as shown in Table II, such cost is not
only acceptable in most cases, but it is also at times negligible
or even negative, especially for Protocol 3. In Protocol 3, when
the total number of clients is large enough, the extra work of
duplication at the client side will not influence the aggregate
write performance since the data servers have already been heavily
loaded and their I/O bandwidth have been saturated. Furthermore,
the application running on a client node will consider its write
operations completed as long as the client has received at least
one acknowledgment among each mirroring pair, although some
duplication work may still proceed, transparent to the
application.
Since the data servers are not dedicated and their CPU, disks,
memory and network load are different, Protocol 3 chooses the
response time of the less heavily loaded server in each mirroring
pair and thus surpass the PVFS with half the number of data
servers.